好程序员-千锋教育旗下高端IT职业教育品牌
官方微信
2022-11-11
节点 namenode zkfc
什么是HA
HA: High Availability,高可用集群,指的是集群7*24小时不间断服务。
为什么需要HA
在HDFS中,有NameNode、DataNode和SecondaryNameNode角色的分布,客户端所有的操作都是要与NameNode交互的,同时整个集群的命名空间信息也都保存在NameNode节点。但是,现在的集群配置中只有一个NameNode,于是就有一个问题: 单点故障
那么,什么是单点故障呢?现在集群中只有一个NameNode,那么假如这个NameNode意外宕机、升级硬件等,导致NameNode不可用了,整个集群是不是也就不可用了?这就是单点故障的问题。
为了解决这样的问题,就需要高可用集群了。
高可用的备份方式
●主从模式(冷备)
准备两台服务器, 准备相同的程序。 一台服务器对外提供服务, 称为主节点(Active节点); 另外一台服务器平时不对外提供服务, 主要负责和Active节点之间进行数据的同步, 称为备份节点(Standby节点). 当主节点出现故障, Standby节点可以自动提升为Active节点, 对外提供服务。 ZooKeeper实现的集群高可用, 采用的就是这种模式。
我作为一个班级的讲师,在班级负责授课的工作。如果我有一天生病请假了,是不是咱们班级就得自习一天了?为了解决这样的问题,教学部安排另外一个讲师,每天跟着我。我上课讲课,他就在旁边听着;我上课提问问题,他就在旁边看着;我去吃饭,他也在旁边跟着;我去上个厕所,他也在跟着!做为我的一个影子存在着。由于这个同时每天都会跟着我,因此我的一言一行,讲了什么内容,留了什么作业,吃了什么饭,抽了几根烟,他都知道!那么,如果有一天我生病请假了,他是不是就可以直接替代我为班级上课呢?
●双主互备(热备)(了解)
准备两台服务器, 准备相同的程序. 同时对外提供服务(此时, 这两台服务器彼此为对方的备份), 这样, 当一台节点宕机的时候, 另外一台节点还可以继续提供服务.
小明到肯德基吃饭,找服务员点餐,这是正常的流程。但是,如果服务员只有一个,并且恰好生病了,那么小明是不是将没有办法正常点餐了。为了解决这个问题,肯德基雇了两个服务员,同时提供服务,这样一个服务员出问题了,另外一个服务员依然可以提供服务。
●集群多备(了解)
基本上等同于双主互备, 区别就在于同时对外提供服务的节点数量更多, 备份数量更多 肯德基觉得两个服务员也不保险,有两个同时生病的可能性,于是又多雇了几个服务员。
高可用的实现
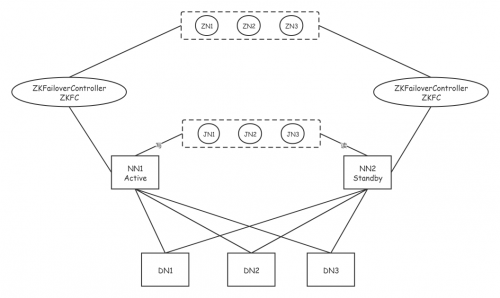
我们在这里采用的是主从模式的备份方式,也就是准备两个NameNode,一个对外提供服务,称为Active节点;另外一个不对外提供服务,只是实时的同步Active节点的数据,称为Standby的节点。
为了提供快速的故障转移,Standby节点还必须具有集群中块位置的最新信息。为了实现这一点,DataNodes被配置了两个NameNodes的位置,并向两者发送块位置信息和心跳信号。也就是说,DataNode同时向两个NameNode心跳反馈。
高可用架构图
ZN1ZN3ZN2ZKFAILOVERCONTROLLERZKFAILOVERCONTROLLERZKFCZKFCJN3JN1JN2NN1NN2STANDBYACTIVEDN2DN3DN1
JournalNode
●JournalNode的功能
Hadoop2.x版本之后, Clouera提出了QJM/QuromJournal Manager, 这是一个基于Paxos算法实现的HA的实现方案 1. 基本的原理就是使用2N+1台JN存储EditLog, 每次写入数据的时候, 有半数以上的JN返回成功的信息, 就表示本次的操作已经同步到了JN 2. 在HA中, SecondaryNameNode这个角色已经不存在了, 保证Standby节点的元数据信息与Active节点的元数据信息一致, 需要通过若干个JN 3. 当有任何的操作发生在Active节点上的时候, JN会记录这些操作到半数以上的节点中. Standby节点检测JN中的log日志文件发生了变化, 会读取JN中的数据到自己的内存中, 维护最新的目录树结构与元数据信息 4. 当发生故障的时候, Active节点挂掉, 此时Standby节点在成为新的Active节点之前, 会将读取到的EditLog文件在自己的内存中进行推演, 得到最新的目录树结构. 此时再升为Active节点, 可以无缝的继续对外提供服务.
●防止脑裂的发生
对于HA群集的正确操作至关重要,一次只能有一个NameNode处于Active状态。否则,名称空间状态将在两者之间迅速分散,从而有数据丢失或其他不正确结果的风险。为了确保该属性并防止所谓的“裂脑情况”,JournalNode将一次仅允许单个NameNode成为作者。在故障转移期间,变为活动状态的NameNode将仅承担写入JournalNodes的角色,这将有效地防止另一个NameNode继续处于活动状态,从而使新的Active可以安全地进行故障转移。 - 怎么理解脑裂? 就是Active节点处于网络震荡状态,假死状态,Standby就转为Active。等网络震荡过后,就有两个Active了,这就是脑裂。
●JournalNode集群正常工作的条件
- 至少3个Journalnode节点 - 运行个数建议奇数个(3,5,7等) - 满足(n+1)/2个以上,才能正常服务。即能容忍(n-1)/2个故障。
●JournalNode的缺点
在这种模式下,即使活动节点发生故障,系统也不会自动触发从活动NameNode到备用NameNode的故障转移,必须需要人为的操作才行。要是有一个能监视Active节点的服务功能就好了。 这个时候,我们就可以使用zookeeper集群服务,来帮助我们进行自动容灾了。
自动容灾原理
如果想进行HA的自动故障转移,那么需要为HDFS部署两个新组件:ZooKeeper quorum和ZKFailoverController进程(缩写为ZKFC)
Zookeeper quorum
Apache ZooKeeper是一项高可用性服务,用于维护少量的协调数据,将数据中的更改通知客户端并监视客户端的故障。HDFS自动故障转移的实现依赖ZooKeeper进行以下操作:
- 故障检测 集群中的每个NameNode计算机都在ZooKeeper中维护一个持久性会话。如果计算机崩溃,则ZooKeeper会话将终止,通知另一个NameNode应触发故障转移。 - 活动的NameNode选举(HA的第一次启动) ZooKeeper提供了一种简单的机制来专门选举一个节点为活动的节点。如果当前活动的NameNode崩溃,则另一个节点可能会在ZooKeeper中采取特殊的排他锁,指示它应成为下一个活动的NameNode。
ZKFC
ZKFailoverController(ZKFC)是一个新组件,它是一个ZooKeeper客户端,它监视和管理namenode的状态。运行namenode的每台机器都会运行一个ZKFC,该ZKFC负责以下内容:
- 运行状况监视 ZKFC使用运行状况检查命令定期ping其本地NameNode。只要NameNode以健康状态及时响应,ZKFC就会认为该节点是健康的。如果节点崩溃,冻结或以其他方式进入不正常状态,则运行状况监视器将其标记为不正常。 - ZooKeeper会话管理 当本地NameNode运行状况良好时,ZKFC会在ZooKeeper中保持打开的会话。如果本地NameNode处于活动状态,则它还将持有一个特殊的“锁定” znode。该锁使用ZooKeeper对“临时”节点的支持。如果会话到期,则锁定节点将被自动删除。 - 基于ZooKeeper的选举 如果本地NameNode运行状况良好,并且ZKFC看到当前没有其他节点持有锁znode,则它本身将尝试获取该锁。如果成功,则它“赢得了选举”,并负责运行故障转移以使其本地NameNode处于活动状态。故障转移过程类似于上述的手动故障转移:首先,如有必要,将先前的活动节点隔离,然后将本地NameNode转换为活动状态。
自动容灾的过程描述
ZKFC(是一个进程,和NN在同一个物理节点上)有两只手,分别拽着NN和Zookeeper。(监控NameNode健康状态,并向Zookeeper注册NameNode);集群一启动,2个NN谁是Active?谁又是Standby呢? 2个ZKFC先判断自己的NN是否健康,如果健康,2个ZKFC会向zoopkeeper集群抢着创建一个节点,结果就是只有1个会最终创建成功,从而决定active地位和standby位置。如果ZKFC1抢到了节点,ZKFC2没有抢到,ZKFC2也会监控watch这个节点。如果ZKFC1的Active NN异常退出,ZKFC1最先知道,就访问ZK,ZK就会把曾经创建的节点删掉。删除节点就是一个事件,谁监控这个节点,就会调用callback回调,ZKFC2就会把自己的地位上升到active,但在此之前要先确认ZKFC1的节点是否真的挂掉?这就引入了第三只手的概念。 ZKFC2通过ssh远程连接NN1尝试对方降级,判断对方是否挂了。确认真的不健康,才会真的 上升地位之active。所以ZKFC2的步骤是: 1.创建新节点。 2.第三只手把对方降级。 3.把自己升级 那如果NN都没毛病,ZKFC挂掉了呢?Zoopkeeper有一个客户端session机制,集群启动之后,2个ZKFC除了监控自己的NN,还要和Zoopkeeper建立一个tcp长连接,并各自获取自己的session。只要一方的session失效,Zoopkeeper 就会删除该方创建的节点,同时另一方创建节点,上升地位。


 扫码开启架构师蜕变之旅 >>
扫码开启架构师蜕变之旅 >>
开班时间:2021-04-12(深圳)
开班盛况开班时间:2021-05-17(北京)
开班盛况开班时间:2021-03-22(杭州)
开班盛况开班时间:2021-04-26(北京)
开班盛况开班时间:2021-05-10(北京)
开班盛况开班时间:2021-02-22(北京)
开班盛况开班时间:2021-07-12(北京)
预约报名开班时间:2020-09-21(上海)
开班盛况开班时间:2021-07-12(北京)
预约报名开班时间:2019-07-22(北京)
开班盛况
Copyright 2011-2023 北京千锋互联科技有限公司 .All Right
京ICP备12003911号-5
 京公网安备 11010802035720号
京公网安备 11010802035720号













