好程序员-千锋教育旗下高端IT职业教育品牌
官方微信
2022-11-02
配置 redis 开发
1.概述
随着互联网技术的发展,对技术要求也越来越高,所以在当期情况下项目的开发中对数据访问的效率也有了很高的要求,所以在项目开发中缓存技术使用的也越来越多,因为它可以极大的提高系统的访问速度,关于缓存的框架也种类繁多,比如 Redis、Ehchahe、JBoss Cache、Voldemort、Cacheonix 等等,今天主要介绍的是使用现在非常流行的 NoSQL 数据库(Redis)来实现我们的缓存需求
2.SpringBoot 简介
Spring Boot 是由 Pivotal 团队提供的全新框架,其设计目的是用来简化新Spring 应用的初始搭建以及开发过程。该框架使用了特定的方式来进行配置,从而使开发人员不再需要定义样板化的配置。通过这种方式,Spring Boot 致力于在蓬勃发展的快速应用开发领域(rapid application development)成为领导者。
主要特点:
1.创建独立的 Spring 应用程序
2.嵌入的 Tomcat,无需部署 WAR 文件
3.简化 Maven 配置
4.自动配置 Spring
5.提供生产就绪型功能,如指标,健康检查和外部配置
6.绝对没有代码生成和对 XML 没有要求配置
3.Redis 简介
Redis 是一个开源(BSD 许可)的,内存中的数据结构存储系统,它可以用作数据库、缓存和消息中间件,Redis 的优势包括它的速度、支持丰富的数据类型、操作原子性,以及它的通用性。
4.下面就是 SpringBoot 整合 Redis 具体实现步骤
4.1 springBoot整合redis的实现步骤
步骤一: 导入相关依赖
在 Maven 的 pom.xml 文件中加入 Redis 包.配置redis依赖
<!—配置 redis 依赖-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
<version>2.1.5.RELEASE</version>
</dependency>
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-pool2</artifactId>
<version>2.6.2</version>
</dependency>
//依赖解释
Spring-data-redis提供了在Spring应用中通过简单的配置访问redis服务,
RedisTemplate对reids底层开发包(Jedis, JRedis, and RJC,lettuce)进行了高度封装,
封装了 RedisTemplate 对象来进行对Redis的各种操作、异常处理及序列化,支持发布订阅,并对Spring 3.1 cache进行了实现,它支持所有的Redis原生的 API。
步骤二: 配置全局配置文件.配置连接redis的连接参数
server:
port: 80
spring:
cache:
type: redis
redis:
# redis数据库索引(默认为0),我们使用索引为3的数据库,避免和其他数据库冲突
#database: 3
# redis服务器地址(默认为loaclhost)
host: localhost
# redis端口(默认为6379)
port: 6379
# redis访问密码(默认为空)
#password: pwd123
# redis连接超时时间(单位毫秒)
timeout: 3000
# redis连接池配置
pool:
# 最大可用连接数(默认为8,负数表示无限)
max-active: 8
# 最大空闲连接数(默认为8,负数表示无限)
max-idle: 4
# 最小空闲连接数(默认为0,该值只有为正数才有用)
min-idle: 0
# 从连接池中获取连接最大等待时间(默认为-1,单位为毫秒,负数表示无限)
max-wait: -1
步骤三: RedisTemplate模板类对象可以配置,也可以不用配置
回顾redis存储的数据类型,五种值的数据类型,最终以字符串类型的数据存到redis里面.
问题: 向redis存储javaBean, 集合数据等等其他数据.
解决方案:
可以将javaBean, 集合数据等等其他数据转成字符串类型的数据,再存储到redis里面.
具体实现:
springBoot整合redis时,默认使用的JDK序列化类,将对象数据转成string类型数据.(可以不用配置RedisTemplate模板类)
当然可以手动配置RedisTemplate模板类,可以指定序列化类,比如:性能好的JacksonJsonRedisSerializer
可以不用配置, SpringBoot会扫描到该RedisTemplate会初始化这个bean,存到spring容器中.
可以配置RedisTemplate(固定代码)
@Configuration
public class RedisConfig {
/**
* 设置Redis序列化方式,默认使用的JDKSerializer的序列化方式,效率低,这里我们使用 jackson
*
* @param factory
* @return
*/
@Bean
public RedisTemplate<String, Object> redisTemplate(RedisConnectionFactory factory) {
//创建模板类对象
RedisTemplate<String, Object> template = new RedisTemplate<>();
//创建String序列化类
RedisSerializer<String> redisSerializer = new StringRedisSerializer();
//指定使用jackson工具负责具体的序列化操作
Jackson2JsonRedisSerializer jackson2JsonRedisSerializer = new Jackson2JsonRedisSerializer(Object.class);
//创建jackson的核心api的 ObjectMapper ,将bean,list,map,数组等等转成字符串
ObjectMapper om = new ObjectMapper();
//使用objectmapper设置bean的属性,修饰符
om.setVisibility(PropertyAccessor.ALL, JsonAutoDetect.Visibility.ANY);
//设置默认类型
om.enableDefaultTyping(ObjectMapper.DefaultTyping.NON_FINAL);
//设置将本地时间转成字符串
om.disable(SerializationFeature.WRITE_DATES_AS_TIMESTAMPS);
//将核心api objectmapper设置给jackson
jackson2JsonRedisSerializer.setObjectMapper(om);
//通过工厂得到连接对象
template.setConnectionFactory(factory);
//设置key序列化方式: 转成字符串
template.setKeySerializer(redisSerializer);
//设置value序列化: 字符串
template.setValueSerializer(jackson2JsonRedisSerializer);
//value hashmap序列化
template.setHashValueSerializer(jackson2JsonRedisSerializer);
return template;
}
//获取缓存管理器对象:管理缓存
@Bean
public CacheManager cacheManager(RedisConnectionFactory factory) {
RedisSerializer<String> redisSerializer = new StringRedisSerializer();
Jackson2JsonRedisSerializer jackson2JsonRedisSerializer = new Jackson2JsonRedisSerializer(Object.class);
//解决查询缓存转换异常的问题
ObjectMapper om = new ObjectMapper();
om.setVisibility(PropertyAccessor.ALL, JsonAutoDetect.Visibility.ANY);
om.enableDefaultTyping(ObjectMapper.DefaultTyping.NON_FINAL);
jackson2JsonRedisSerializer.setObjectMapper(om);
// 配置序列化(解决乱码的问题),过期时间600秒
RedisCacheConfiguration config = RedisCacheConfiguration.defaultCacheConfig()
.entryTtl(Duration.ofSeconds(600))
.serializeKeysWith(RedisSerializationContext.SerializationPair.fromSerializer(redisSerializer))
.serializeValuesWith(RedisSerializationContext.SerializationPair.fromSerializer(jackson2JsonRedisSerializer))
.disableCachingNullValues();
RedisCacheManager cacheManager = RedisCacheManager.builder(factory)
.cacheDefaults(config)
.build();
return cacheManager;
}
}
步骤三: 可以测试
在测试类里面,注入@RedisTemplate操作redis数据库.
package com.user;
import com.system.SpringApplicationConfig11;
import com.system.user.domain.User;
import org.junit.Test;
import org.junit.runner.RunWith;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.data.redis.core.ListOperations;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.test.context.junit4.SpringRunner;
import org.springframework.util.StringUtils;
import java.util.List;
import java.util.Set;
@RunWith(SpringRunner.class)
@SpringBootTest(classes = {SpringApplicationConfig11.class})
public class DemoRedisTemplate {
@Autowired
private RedisTemplate<String, Object> redisTemplate;
@Test// hash类型: key-value(key-value)就是map
public void testX9(){
redisTemplate.boundHashOps("myhash").put("username","jack");
redisTemplate.boundHashOps("myhash").put("password","1111");
Set<Object> myhash = redisTemplate.boundHashOps("myhash").keys();
System.out.println("获取map的所有key:");
for (Object key : myhash) {
System.out.print(key+",");
}
System.out.println();
List<Object> myhash1 = redisTemplate.boundHashOps("myhash").values();
System.out.println("获取map的所有value");
for (Object value : myhash1) {
System.out.print(value+",");
}
System.out.println();
}
@Test//sortedset类型: redisTemplate
public void testX8(){
redisTemplate.boundZSetOps("myset2withscore").add("jack",10.0);
redisTemplate.boundZSetOps("myset2withscore").add("rose",9.0);
redisTemplate.boundZSetOps("myset2withscore").add("ship",20.0);
Set<Object> myset2withscore = redisTemplate.boundZSetOps("myset2withscore").range(0, -1);
for (Object o : myset2withscore) {
System.out.println(o);
}
}
@Test//set类型: redisTemplate
public void testX7(){
redisTemplate.boundSetOps("myset1noscore").add("jack");
redisTemplate.boundSetOps("myset1noscore").add("jack");
redisTemplate.boundSetOps("myset1noscore").add("rose");
Set<Object> myset1noscore = redisTemplate.boundSetOps("myset1noscore").members();
for (Object o : myset1noscore) {
System.out.println(myset1noscore);
}
}
@Test//list类型的数据: ListOperations
public void testX5(){
Boolean flag = redisTemplate.hasKey("mylist");//判断缓存数据库是否有这个key
System.out.println("mylist:"+flag);
Boolean flag2 = redisTemplate.hasKey("username");//判断缓存数据库是否有这个key
System.out.println("username:"+flag2);
}
@Test//list类型的数据: RedisTemplate
public void testX6(){
redisTemplate.boundListOps("mylist").leftPush("jack");
redisTemplate.boundListOps("mylist").leftPush("rose");
redisTemplate.boundListOps("mylist").rightPush("ship");
List<Object> mylist = redisTemplate.boundListOps("mylist").range(0, -1);
for (Object o : mylist) {
System.out.println(o);
}
}
@Test//list类型的数据: ListOperations
public void testX4(){
redisTemplate.opsForList().leftPush("mylist","jack");
Object mylist = redisTemplate.opsForList().leftPop("mylist");
System.out.println(mylist);
//ListOperations<String, Object> operation= redisTemplate.opsForList();
}
@Test//操作string
public void testX(){
redisTemplate.opsForValue().set("username","jack");//底层用的就是jedis
Object username = redisTemplate.opsForValue().get("username");
System.out.println(username);
}
@Test//操作string
public void testX2(){
redisTemplate.boundValueOps("username").set("rose");//向缓存中设置数据
Object username = redisTemplate.boundValueOps("username").get();
System.out.println(username);
}
@Test//操作string
public void testX3(){
User user2 = new User(10L,"大马猴","dmh@sina.com","666","12");
//底层: 用指定的Jackson2JsonRedisSerializer的objectMapper将user转成json,设置到缓存中
redisTemplate.boundValueOps("user").set(user2);
}
}
RedisTemplate 核心api:
RedisTemplate概述:
RedisTemplate 是 Spring Boot 访问 Redis 的核心组件,底层通过 RedisConnectionFactory 对多种 Redis 驱动进行集成,上层通过 XXXOperations 提供丰富的 [API],操作redis数据库.
问题:
但美中不足的是,需要针对应用场景,使用不同的 RedisSerializer 对RedisTemplate 进行定制,那有没有一种方法能够自动完成 RedisTemplate 的定义呢?
解决方案:
自己配置RedisTemplate,手动指定序列化类.
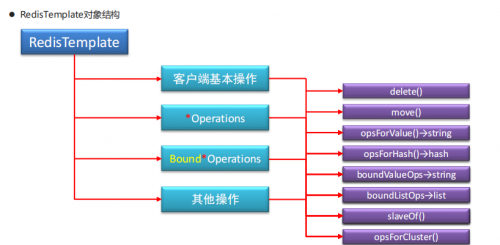
连接池自动管理,提供了一个高度封装的“RedisTemplate”类(会自动初始化到容器中,可以直接使用)。
RedisTemplate默认使用的jdk的序列化
当然也可以指定RedisTemplate的序列化工具
针对jedis客户端中大量api进行了归类封装,将同一类型操作封装为operation操作接口。
操作不同的数据类型,获取不同的operations操作对象.
Jedis的api:
ValueOperations:操作的string类型的数据, 简单K-V操作,底层就是set方法
SetOperations:set类型数据操作.
ZSetOperations:zset类型数据操作
HashOperations:针对map类型的数据操作
ListOperations:针对list类型的数据操作
提供了对key的“bound”(绑定)便捷化操作API,可以通过bound封装指定的key,然后进行一系列的操作而无须“显式”的再次指定Key,即BoundKeyOperations将事务操作封装,由容器控制。
BoundValueOperations
底层封装的就是ValueOperations:操作的string类型的数据, 简单K-V操作,底层就是set方法
BoundSetOperations
底层封装的就是SetOperations:set类型数据操作.
BoundListOperations
底层封装的就是ZSetOperations:zset类型数据操作
BoundSetOperations
底层封装的就是ZSetOperations:zset类型数据操作
BoundHashOperations
底层封装的就是HashOperations:针对map类型的数据操作
针对数据的“序列化/反序列化”,提供了多种可选择策略(RedisSerializer)
JdkSerializationRedisSerializer:POJO对象的存取场景,使用JDK本身序列化机制,将pojo类通过ObjectInputStream/ObjectOutputStream进行序列化操作,最终redis-server中将存储字节序列。是目前最常用的序列化策略。
缺点: 性能差,不能对本地日期类型进行转换.
StringRedisSerializer:Key或者value为字符串的场景,根据指定的charset对数据的字节序列编码成string,是“new String(bytes, charset)”和“string.getBytes(charset)”的直接封装。是最轻量级和高效的策略。
JacksonJsonRedisSerializer:jackson-json工具提供了javabean与json之间的转换能力,可以将pojo实例序列化成json格式存储在redis中,也可以将json格式的数据转换成pojo实例。因为jackson工具在序列化和反序列化时,需要明确指定Class类型,因此此策略封装起来稍微复杂。【需要jackson-mapper-asl工具支持】
OxmSerializer:提供了将javabean与xml之间的转换能力,目前可用的三方支持包括jaxb,apache-xmlbeans;redis存储的数据将是xml工具。不过使用此策略,编程将会有些难度,而且效率最低;不建议使用。【需要spring-oxm模块的支持】
如果你的数据需要被第三方工具解析,那么数据应该使用StringRedisSerializer而不是JdkSerializationRedisSerializer。
注意小结:
如果向缓存中添加javaBean对象时,一定要让javaBean实现Serializable 接口
4.2 Service 层应用缓存之springBoot整合缓存
为什么要springBoot整合缓存Cache.
通过Cache保存数据, 提高数据的响应效率.
实现本质:
第一步: 第一次需要从关系型数据库里面把数据查询查询出来, 设置到缓存中
第二步: 下次再查询数据时,不在查询关系型数据库中,而是从缓存中取出数据
存在问题:
比如: 第一次从mysql中查询了100条数据,存到缓存中有100条数据
比如: 下次再查询之前,删除了一条数据,mysql剩余99条数据, 缓存中依然了100条数据
解决方案:
如果关系型数据库中的数据发生了变化,需要同步更新缓存数据(让关系型数据库的数据与redis缓存的数据同步)
在企业中解决方案:
解决方案一: 通过手写缓存代码,实现缓存数据的存取以及缓存数据的同步更新(代码冗余)
解决方案二: 通过springBoot整合缓存,实现缓存数据的自动存储,以及自动同步更新.
具体的整合步骤:
缓存常用的注解
@Cacheable: 先从缓存中查询数据,如果缓存中没有数据,这时从关系型数据库查询数据,设置到缓存中.
@CachePut: 先从关系型数据库中查询数据,清空缓存中的数据,把返回的数据再次设置到缓存中
实现缓存的同步更新.
注意细节:
@CachePut通常操作的添加方法和更新方法
@CachePut要求缓存的key要保持一致.
当执行添加一条数据和修改一条数据时,使用@CachePut注解,key使用id
实现缓存的同步更新
第一步: 添加id=13L的数据, 设置到缓存中.
第二步: 修改id=13L的数据, 比如: 修改username=jack, 缓存会自动同步更新为jack.
@CachePut和@Cacheable一般不建议放在一块使用.
@Cacheable和@CachePut一块使用时,不会实现缓存的同步更新
解决@Cacheable和@CachePut实现缓存的同步更新,
第一步: 执行查询操作,设置10条数据到缓存中
第二步: 执行添加一条数据操作, 设置1条数据到缓存中,手动更新缓存,实现缓存的同步, 最终缓存了11条数据
解决方案:
修改添加方法,将添加方法的返回值与查询方法的返回值保持一致
如果不一致,会出现类型转换异常.

在添加方法中,执行完添加后,再次查询数据库,最终实现缓存的同步
@CachePut(cacheNames = "listA" ,key="'aa'")
public List<User> addUser2(User user){
//1.先添加
userMapper.insert(user);
//2.再查询
List<User> users = userMapper.selectAll();
return users;
}
@CacheEvict: 直接清空缓存中的数据
步骤一: 导入依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-cache</artifactId>
</dependency>
步骤二: 在引导类上面使用
("com.dao")
//开启缓存支持
public class SpringApplicationConfig {
public static void main(String[] args){
//自动扫描包, 自动装配,启动tomcat插件
SpringApplication.run(SpringApplicationConfig.class);
}
}
步骤三: 使用缓存注解
@Service
public class TestService {
@Autowired
private PersonRepo personRepo;
/**
* @Cacheable 应用到读取数据的方法上,先从缓存中读取,如果没有再从 DB 获取数据,然后把数据添加到缓存中
* unless 表示条件表达式成立的话不放入缓存
*/
@Cacheable(value = "user", key = "#root.targetClass + #username", unless = "#result eq null" , condition="") public Person getPersonByName(String username) {
Person person = personRepo.getPersonByName(username); return person;
}
/**
* @CachePut 应用到写数据的方法上,如新增方法,调用方法时会自动把相应的数据放入缓存,同步更新缓存
为什么没有更新缓存
因为CachePut是方法运行完成之后然后再往缓存中放入数据,所以使用以下的方式进行操作
这个是以方法的参数ID进行缓存操作,当然还可以使用下面这种方式进行操作。拿出返回值的id。在这里需要注意的一点是Cacheable的key是不能用#result取出对应的返回值的。
*/
@CachePut(value = "user", key = "#person.id", unless = "#person eq null")
public Person savePerson(Person person) {
return personRepo.savePerson(person);
}
/**
* @CacheEvict 应用到删除或者修改数据的方法上,调用方法时会将指定key的缓存数据清空, 再次重新查询数据库
*/
@CacheEvict(value = "user", key = "#root.targetClass + #username", condition = "#result eq true")
public boolean removePersonByName(String username) {
return personRepo.removePersonByName(username) > 0;
}
public boolean isExistPersonName(Person person) {
return personRepo.existPersonName(person) > 0;
}
总结:
@Cacheable源码实现
@Cacheable(cacheNames = "listA",key = "'aa'")
public List<User> findUsers(){
List<User> list = userMapper.selectAll();
return list;
}
//源码(手动整合缓存的话,一般使用Ehcache)
//1.通过缓存管理器得到指定名称的缓存
Cache cache = cacheManager.getCache("listA");
//2.通过指定名称: 获取保存数据的缓存区域
Cache.ValueWrapper cacheValue = cache.get("aa");
if(cacheValue!=null){
//3.根据key从缓存中查询数据
//3.1 判断缓存中有没有数据
//3.2 缓存中有数据,说明不是第一次访问
Object o = cacheValue.get();
System.out.println(o);
System.out.println("将从缓存中拿出的数据响应到前台页面");
}else{
//3.3 缓存中没有数据,说明是第一次访问,查询mysql的数据,存到缓存
List<User> users = userMapper.selectAll();
//3.4 将users集合转成json,存到缓存中
String json ="";
//将json存到缓存里面
}
总结
@Cacheable属性说明:
cacheNames/value :用来指定缓存组件的名字
key :缓存数据时使用的 key,可以用它来指定。默认是使用方法参数的值。(这个 key 你可以使用 spEL 表达式来编写)
keyGenerator :key 的生成器。 key 和 keyGenerator 二选一使用, 需要自定义bean生成key
cacheManager :可以用来指定缓存管理器。从哪个缓存管理器里面获取缓存。
condition :可以用来指定符合条件的情况下才缓存
unless :否定缓存。当 unless 指定的条件为 true ,方法的返回值就不会被缓存。当然你也可以获取到结果进行判断。(通过 #result 获取方法结果)
sync :是否使用异步模式。
缓存注解源码
// @since 3.1 可以标注在方法上、类上 下同
@Target({ElementType.METHOD, ElementType.TYPE})
@Retention(RetentionPolicy.RUNTIME)
@Inherited
@Documented
public @interface Cacheable {//缓存查询 作用: 先查询缓存,没有再查询关系数据库存到缓存
// 缓存名称 可以写多个~
@AliasFor("cacheNames")
String[] value() default {};
@AliasFor("value")
String[] cacheNames() default {};
// 支持写SpEL,切可以使用#root
String key() default "";
// Mutually exclusive:它和key属性互相排斥。请只使用一个
String keyGenerator() default "";
String cacheManager() default "";
String cacheResolver() default "";
// SpEL,可以使用#root。 只有true时,才会作用在这个方法上
String condition() default "";
// 可以写SpEL #root,并且可以使用#result拿到方法返回值~~~
String unless() default "";
// true:表示强制同步执行。(若多个线程试图为**同一个键**加载值,以同步的方式来进行目标方法的调用)
// 同步的好处是:后一个线程会读取到前一个缓存的缓存数据,不用再查库了~~~
// 默认是false,不开启同步one by one的
// @since 4.3 注意是sync而不是Async
// 它的解析依赖于Spring4.3提供的Cache.get(Object key, Callable<T> valueLoader);方法
boolean sync() default false;
}
@Target({ElementType.METHOD, ElementType.TYPE})
@Retention(RetentionPolicy.RUNTIME)
@Inherited
@Documented
public @interface CachePut {//缓存更新: 先查询数据库,然后更新缓存
@AliasFor("cacheNames")
String[] value() default {};
@AliasFor("value")
String[] cacheNames() default {};
// 注意:它和上面区别是。此处key它还能使用#result
String key() default "";
String keyGenerator() default "";
String cacheManager() default "";
String cacheResolver() default "";
String condition() default "";
String unless() default "";
}
Target({ElementType.METHOD, ElementType.TYPE})
@Retention(RetentionPolicy.RUNTIME)
@Inherited
@Documented
public @interface CacheEvict {//缓存清除
@AliasFor("cacheNames")
String[] value() default {};
@AliasFor("value")
String[] cacheNames() default {};
// 它也能使用#result
String key() default "";
String keyGenerator() default "";
String cacheManager() default "";
String cacheResolver() default "";
String condition() default "";
// 是否把上面cacheNames指定的所有的缓存都清除掉,默认false
boolean allEntries() default false;
// 是否让清理缓存动作在目标方法之前执行,默认是false(在目标方法之后执行)
// 注意:若在之后执行的话,目标方法一旦抛出异常了,那缓存就清理不掉了~~~~
boolean beforeInvocation() default false;
}
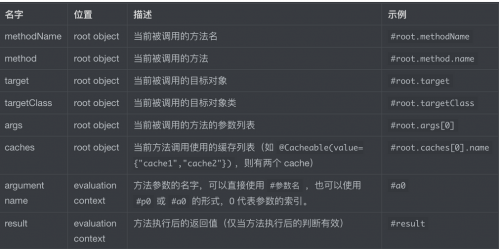
spEL 编写 key或者condition或者unless属性,可以使用下面的对象
注意: key属性里面,可以使用下面图片的对象, condition属性不能全部使用下面图片的对象, unless也一样
@Cacheable的condition 属性能使用的SpEL语言只有#root和获取参数类的SpEL表达式,不能使用返回结果的#result 。所以 condition = "#result != null" 会导致所有对象都不进入缓存,每次操作都要经过数据库。
@Cacheable的unless属性可以使用#result表达式。 效果: 缓存如果有符合要求的缓存数据则直接返回,没有则去数据库查数据,查到了就返回并且存在缓存一份,没查到就不存缓存。
4.3 数据访问资源类
@Component
@Path("personMgr")
public class PersonMgrResource {
@Autowired
private PersonService personService;
@GET
@Path("getPersonByName")
@Produces(MediaType.APPLICATION_JSON)
public JsonResp getPersonByName(@QueryParam("username") String username) {
Person person = personService.getPersonByName(username);
return JsonResp.success(person);
}
@POST
@Path("removePersonByName")
@Produces(MediaType.APPLICATION_JSON)
public JsonResp removePersonByName(@QueryParam("username") String username) {
if(personService.removePersonByName(username)) {
return JsonResp.success();
}
return JsonResp.fail("系统错误!");
}
@POST
@Path("savePerson")
@Produces(MediaType.APPLICATION_JSON)
public JsonResp savePerson(Person person) {
if (personService.isExistPersonName(person)) {
return JsonResp.fail("用户名已存在!");
}
if (personService.savePerson(person).getId() > 0) {
return JsonResp.success();
}
return JsonResp.fail("系统错误!");
}
}
5.通过 postman 工具来测试缓存是否生效
第一次访问查找用户:
第一次通过用户名称来查找用户可以看到是从库中查询的数据,我们可以通过 RedisClient 工具来查看数据已放入了缓存
第二次查找用户:发现服务端并未打印任何数据库查询日志,可以知道第二次查询是从缓存中查询得到的数据。
总结
本文介绍如何通过 SpringBoot 来一步步集成 Redis 缓存,关于 Redis 的使用它不仅可以用作缓存,还可以用来构建队列系统,Pub/Sub 实时消息系统,分布式系统的的计数器应用,关于 Redis 更多的介绍,请前往官网查阅。
下一篇:大数据的5V特征


 扫码开启架构师蜕变之旅 >>
扫码开启架构师蜕变之旅 >>
开班时间:2021-04-12(深圳)
开班盛况开班时间:2021-05-17(北京)
开班盛况开班时间:2021-03-22(杭州)
开班盛况开班时间:2021-04-26(北京)
开班盛况开班时间:2021-05-10(北京)
开班盛况开班时间:2021-02-22(北京)
开班盛况开班时间:2021-07-12(北京)
预约报名开班时间:2020-09-21(上海)
开班盛况开班时间:2021-07-12(北京)
预约报名开班时间:2019-07-22(北京)
开班盛况
Copyright 2011-2023 北京千锋互联科技有限公司 .All Right
京ICP备12003911号-5
 京公网安备 11010802035720号
京公网安备 11010802035720号













